
Occasionally, parallel strands of technological development come together to yield unanticipated benefits in areas for which the technology was not specifically designed. Think of advances in the textile industry, during the Industrial Revolution. Or the genius of microwave popcorn.
In this first of a two-part report, we’ll be looking at how the development of self-educating algorithms is combining with the emergence of cloud technology as the new medium for data storage and application delivery, to make it possible for network infrastructures to essentially manage themselves, in the near future.
Managing Big Data
We’ve heard a lot in the industry press and the general media, about Big Data: the humongous volumes of structured and largely unstructured information gathered through corporate networks, purchasing chains, biometric recordings, time-tracking and location data, online activities, and any number of other sources with which people interact.
Gathering information is only part of the picture. As Business Intelligence (BI) analysts have come to realise, it’s necessary to perform complex, continuous, and in some cases counter-intuitive analytical processes on Big Data, in order to extract valuable insights from it. And to meet this challenge, conventional software tools and human intelligence simply aren’t enough.
Not Managing Big Hardware
What’s emerged as standard wisdom is that Big Data requires Big Compute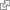 : processing power that’s of a comparably large scale – and often distributed – to cope with the sheer volumes of information and analytical operations.
: processing power that’s of a comparably large scale – and often distributed – to cope with the sheer volumes of information and analytical operations.
The industry standard Hadoop analytics platform goes some way towards easing this burden. Its trademark stacks and MapReduce allow data analysis to be spread over a large array of cheap generic servers, in a batch-oriented system that reduces some of the donkey work, but doesn’t do so well with real-time functions such as stream processing, interactive applications, or more complex analyses.
At this point, the Cloud comes into the picture, to assist in coping with the scale of what’s involved. Cloud-based infrastructures have emerged, with remotely hosted banks of servers, computational resources and software for data storage and analysis – with the multiplication factor allowing for the processing power needed to accommodate the multiplying number of data sources.
 Adding IoT to the Mix
Adding IoT to the Mix
And with the emergence of the Internet of Things or IoT, those data sources just keep coming. Performance-tracking wearables, smart household appliances, communicative self-driving vehicles, consumables that can tell you what they contain, and where they are – the pool of potentially insightful data is set to grow, rather than diminish. Some figures suggest that the equivalent of the entire Google search engine’s worth of data is being created every four days.
And the analytical tools required to extract value from it will need to step up their game, and become just as smart as the data sources that they’re analysing – or hopefully smarter.
A Dose of Intelligence
The evolving landscape of smart and responsive devices and technologies demands analytical processes and tools that lend themselves to observations and reactions at the human scale. Data analytics engines will need to be in memory, and in parallel with the data pools that they’re addressing. And analytics systems will have to perform iterations on a continuous basis, and be adaptive and responsive to change, themselves.
In essence, the new breed of analytics tools will need to be capable of learning.
Learning Machines
Machine learning is a term widely used in computer science and other disciplines, describing a process whereby low-level algorithms are employed to uncover patterns implicit within pools of data. It’s analogous to the process that occurs in human thought, where we learn from our life experiences, rather than from specific sets of lessons or instructions.
Information is fed into the system as classifiers, which are represented in some form of language that the computer can understand. Objective or scoring functions are applied to these classifiers, to evaluate them as good or bad. Then optimisation techniques are applied to the results, to isolate the highest scoring functions. These may then be carried forward as the basis of further decision-making action, on the part of the system.
It’s machines (systems and software), learning by inference or implication; the machine learning algorithms uncover the best ways to perform complex tasks by generalising from a learned database of examples. Generally speaking, the more data (examples) you have available, the bigger the range of complex tasks that may be performed. So, Big Data working in tandem with Machine Learning may provide analytics with a huge array of tools and techniques.
At the heart of a machine learning process is the system’s ability to make generalisations that go beyond the data in its initial training set. Though having a lot of data available helps, it’s not the crucial factor to a system’s performance. Rather, it is the range of features available to the system as a whole – and the way these features interact – that has the greatest impact on its ability to learn.
 Looking Ahead
Looking Ahead
With their ability to adapt to changing conditions, and to respond to activities at the human scale (some in real time), learning machines are well placed to become the basis for analytics tools that can predict the logical outcome of certain sequences of observations and events, from their exploration, visualisation, modelling, querying, and retesting of the data to which they’re exposed.
This predictive analysis may not only extrapolate future outcomes from current information, but also uncover hidden issues or outcomes which may be inferred from known data sources.
It’s this predictive element that has great potential in the management of complex systems such as network infrastructures. And it’s infrastructure analytics using machine intelligence that will be the focus of the concluding part of this report.
Des Nnorchiri
Des Nnochiri has a Master’s Degree (MEng) in Civil Engineering with Architecture, and spent several years at the Architectural Association, in London. He views technology with a designer’s eye, and is very keen on software and solutions which put a new wrinkle on established ideas and practices. He now writes for markITwrite across the full spectrum of corporate tech and design. In previous lives, he has served as a Web designer, and an IT consultant to The Learning Paper, a UK-based charity extending educational resources to underprivileged youngsters in West Africa. A film buff and crime fiction aficionado, Des moonlights as a novelist and screenwriter. His short thriller, “Trick” was filmed in 2011 by Shooting Incident Productions, who do location work on “Emmerdale”.